โมเดลภาษาคืออะไร
แอปพลิเคชัน AI ที่สร้างขึ้นนั้นขับเคลื่อนโดย โมเดลภาษาซึ่งเป็นแบบจําลองการเรียนรู้ของเครื่องชนิดพิเศษที่คุณสามารถใช้เพื่อดําเนินการ การประมวลผลภาษาธรรมชาติ (NLP) รวมถึง:
- การกําหนด ความรู้สึก หรือการจัดประเภทข้อความภาษาธรรมชาติ
- การสรุปข้อความ
- การเปรียบเทียบแหล่งข้อมูลข้อความหลายแหล่งเพื่อความคล้ายคลึงกันเชิงความหมาย
- สร้างภาษาธรรมชาติใหม่
ในขณะที่หลักการทางคณิตศาสตร์ที่อยู่เบื้องหลังโมเดลภาษาเหล่านี้อาจซับซ้อน แต่ความเข้าใจพื้นฐานของสถาปัตยกรรมที่ใช้ในการนําไปใช้สามารถช่วยให้คุณเข้าใจแนวคิดเกี่ยวกับวิธีทํางานได้
แบบจําลอง Transformer
แบบจําลองการเรียนรู้ของเครื่องสําหรับการประมวลผลภาษาธรรมชาติมีการพัฒนามานานหลายปี แบบจําลองภาษาขนาดใหญ่ที่ทันสมัยของวันนี้จะขึ้นอยู่กับสถาปัตยกรรม Transformer ซึ่งสร้างขึ้นและขยายเทคนิคบางอย่างที่ได้รับการพิสูจน์แล้วว่าประสบความสําเร็จในการสร้างแบบจําลอง คําศัพท์ เพื่อสนับสนุนงาน NLP และโดยเฉพาะอย่างยิ่งในการสร้างภาษา แบบจําลอง Transformer ได้รับการฝึกฝนด้วยข้อความจํานวนมากทําให้สามารถแสดงความสัมพันธ์เชิงความหมายระหว่างคําและใช้ความสัมพันธ์เหล่านั้นเพื่อกําหนดลําดับของข้อความที่สมเหตุสมผล โมเดล Transformer ที่มีคําศัพท์ขนาดใหญ่พอมีความสามารถในการสร้างการตอบสนองภาษาที่ยากต่อการแยกความแตกต่างจากการตอบสนองของมนุษย์
สถาปัตยกรรมแบบจําลอง Transformer ประกอบด้วยส่วนประกอบสองส่วน หรือ บล็อก:
- บล็อก ตัวเข้ารหัส ที่สร้างการแสดงความหมายของคําศัพท์การฝึกอบรม
- บล็อก ตัวถอดรหัส ที่สร้างลําดับภาษาใหม่
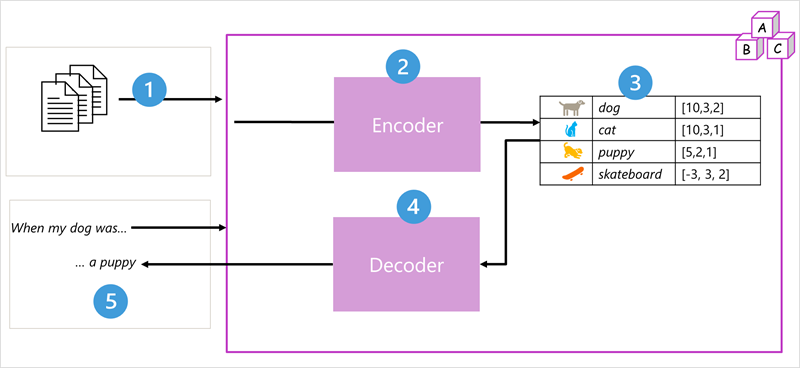
- แบบจําลองได้รับการฝึกด้วยข้อความภาษาธรรมชาติจํานวนมากซึ่งมักมาจากอินเทอร์เน็ตหรือแหล่งข้อมูลสาธารณะอื่น ๆ
- ลําดับของข้อความจะถูกแบ่งออกเป็นโทเค็น (เช่น คำแต่ละคำ) บล็อกตัวเข้ารหัสจะประมวลผลลำดับโทเค็นเหล่านี้โดยใช้เทคนิคที่เรียกว่าการใส่ใจเพื่อกำหนดความสัมพันธ์ระหว่างโทเค็น (เช่น โทเค็นใดที่มีอิทธิพลต่อการมีอยู่ของโทเค็นอื่นในลำดับ โทเค็นที่แตกต่างกันที่มักใช้ในบริบทเดียวกัน และอื่นๆ)
- ผลลัพธ์จากตัวเข้ารหัสคือคอลเลกชันของเวกเตอร์ (อาร์เรย์ตัวเลขแบบหลายค่า) ซึ่งแต่ละองค์ประกอบของเวกเตอร์แสดงถึงแอตทริบิวต์เชิงความหมายของโทเค็น เวกเตอร์เหล่านี้เรียกว่า Embeddings
- บล็อกตัวถอดรหัสทํางานบนลําดับใหม่ของโทเค็นข้อความ และใช้การฝังที่สร้างขึ้นโดยตัวเข้ารหัสเพื่อสร้างผลลัพธ์ภาษาธรรมชาติที่เหมาะสม
- ตัวอย่างเช่น กําหนดลําดับการป้อนข้อมูล เช่น "เมื่อสุนัขของฉันถูก" โมเดลสามารถใช้เทคนิคความสนใจในการวิเคราะห์โทเค็นอินพุตและแอตทริบิวต์ความหมายที่เข้ารหัสในการฝังเพื่อคาดการณ์ความสมบูรณ์ที่เหมาะสมของประโยค เช่น "ลูกสุนัข"
ในทางปฏิบัติ การใช้งานเฉพาะของสถาปัตยกรรมแตกต่างกัน ตัวอย่างเช่น การแสดงตัวเข้ารหัสแบบสองทิศทางจากแบบจําลอง Transformer (BERT) ที่พัฒนาโดย Google เพื่อสนับสนุนเครื่องมือค้นหาของพวกเขาใช้เฉพาะบล็อกตัวเข้ารหัสในขณะที่แบบจําลองการแปลงข้อมูลแบบกําหนดล่วงหน้าที่สร้าง (GPT) ที่พัฒนาโดย OpenAI ใช้เฉพาะบล็อกตัวถอดรหัสเท่านั้น
ในขณะที่คําอธิบายที่สมบูรณ์ของแบบจําลอง Transformer ทุกแง่มุมอยู่นอกขอบเขตของโมดูลนี้ คําอธิบายขององค์ประกอบสําคัญบางอย่างในหม้อแปลงสามารถช่วยให้คุณเข้าใจว่าแบบจําลองดังกล่าวสนับสนุน AI ที่ก่อให้เกิดได้อย่างไร
การแปลงโทเค็น
ขั้นตอนแรกในการฝึกแบบจําลอง Transformer คือการแยกย่อยข้อความการฝึกเป็น โทเค็น กล่าวคือระบุค่าข้อความที่ไม่ซ้ำกันแต่ละค่า เพื่อความเรียบง่ายคุณสามารถนึกภาพของแต่ละคําที่แตกต่างกันในข้อความการฝึกอบรมเป็นโทเค็น (แม้ว่าในความเป็นจริงโทเค็นสามารถสร้างขึ้นสําหรับคําบางส่วนหรือการรวมคําและเครื่องหมายวรรคตอน)
ตัวอย่างเช่น พิจารณาประโยคต่อไปนี้:
I heard a dog bark loudly at a cat
ในโทเค็นข้อความนี้ คุณสามารถระบุคําที่ไม่ต่อเนื่องแต่ละคําและกําหนด ID โทเค็นให้กับคําเหล่านั้นได้ ตัวอย่างเช่น:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- *("a" is already tokenized as 3)*
- cat (8)
ในตอนนี้ คุณสามารถแสดงประโยคด้วยโทเค็น: {1 2 3 4 5 6 7 3 8} ในทํานองเดียวกันประโยค "ฉันได้ยินแมว" อาจถูกแสดงเป็น {1 2 3 8}
เมื่อคุณยังคงฝึกแบบจําลอง โทเค็นใหม่แต่ละโทเค็นในข้อความการฝึกจะถูกเพิ่มลงในคําศัพท์ด้วยรหัสโทเค็นที่เหมาะสม:
- เหมียว (9)
- สเก็ตบอร์ด (10)
- และอื่นๆ...
ด้วยชุดข้อความการฝึกอบรมขนาดใหญ่พอจึงสามารถรวบรวมคําศัพท์ของโทเค็นหลายพันโทเค็นได้
Embeddings
แม้ว่าอาจจะสะดวกในการแสดงโทเค็นเป็นรหัสอย่างง่าย โดยพื้นฐานแล้วจะสร้างดัชนีสําหรับคําศัพท์ทั้งหมดในคําศัพท์ แต่ก็ไม่ได้บอกอะไรเราเกี่ยวกับความหมายของคําหรือความสัมพันธ์ระหว่างคําเหล่านั้น ในการสร้างคำศัพท์ที่รวบรวมความสัมพันธ์เชิงความหมายระหว่างโทเค็น เรากําหนดเวกเตอร์ตามบริบทที่เรียกว่า Embeddings ให้กับโทเค็นเหล่านั้น เวกเตอร์คือการแสดงข้อมูลเชิงตัวเลขที่มีค่าหลายค่า เช่น [10, 3, 1] โดยที่องค์ประกอบตัวเลขแต่ละตัวจะแสดงถึงแอตทริบิวต์เฉพาะของข้อมูล สําหรับโทเค็นภาษา แต่ละองค์ประกอบของเวกเตอร์ของโทเค็นแสดงแอตทริบิวต์ความหมายบางอย่างของโทเค็น หมวดหมู่เฉพาะสําหรับองค์ประกอบของเวกเตอร์ในโมเดลภาษาจะถูกกําหนดในระหว่างการฝึกตามวิธีการใช้คําร่วมกันหรือในบริบทที่คล้ายกัน
เวกเตอร์เป็นตัวแทนของเส้นในพื้นที่หลายมิติซึ่งอธิบาย ทิศทาง และ ระยะทาง ตามแกนหลายแกน (คุณสามารถสร้างความประทับใจให้เพื่อนทางคณิตศาสตร์ของคุณโดยการเรียก ความกว้าง และ ขนาด) อาจเป็นประโยชน์ที่จะคิดถึงองค์ประกอบในเวกเตอร์การฝังสําหรับโทเค็นเป็นการแสดงขั้นตอนตามเส้นทางในพื้นที่หลายมิติ ตัวอย่างเช่น เวกเตอร์ที่มีสามองค์ประกอบแสดงเส้นทางในพื้นที่ 3 มิติที่ค่าองค์ประกอบระบุหน่วยที่เดินทางไปข้างหน้า/ย้อนกลับ ซ้าย/ขวา และขึ้น/ลง โดยรวมเวกเตอร์อธิบายทิศทางและระยะทางของเส้นทางจากต้นกําเนิดไปยังจุดสิ้นสุด
องค์ประกอบของโทเค็นในช่องว่างการฝังแต่ละรายการแสดงถึงแอตทริบิวต์เชิงความหมายบางอย่างของโทเค็น ดังนั้น โทเค็นที่มีความหมายคล้ายคลึงกันควรส่งผลให้เกิดเวกเตอร์ที่มีทิศทางที่คล้ายกัน กล่าวอีกนัยหนึ่งคือ เวกเตอร์เหล่านั้นชี้ไปในทิศทางเดียวกัน เทคนิคที่เรียกว่า ความคล้ายคลึงกันของโคไซน์ ใช้เพื่อตรวจสอบว่าเวกเตอร์สองตัวมีทิศทางที่คล้ายกันหรือไม่ (โดยไม่คํานึงถึงระยะทาง) จึงเป็นตัวแทนคําที่เชื่อมโยงกันในเชิงความหมาย ตัวอย่างง่ายๆ สมมติว่าการฝังสําหรับโทเค็นของเราประกอบด้วยเวกเตอร์ที่มีสามองค์ประกอบ ตัวอย่างเช่น:
- 4 ("สุนัข"): [10,3,2]
- 8 ("แมว"): [10,3,1]
- 9 ("ลูกสุนัข"): [5,2,1]
- 10 (“สเก็ตบอร์ด”): [-3,3,2]
เราสามารถลงจุดเวกเตอร์เหล่านี้ในพื้นที่สามมิติเช่นนี้:
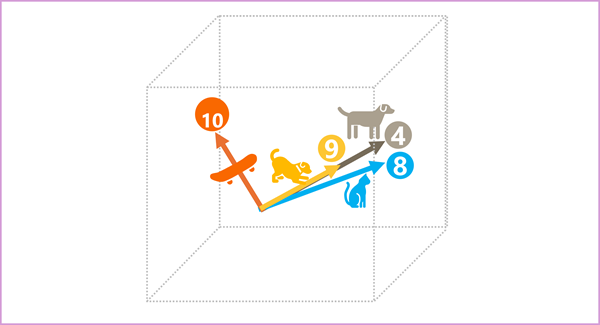
เวกเตอร์ฝังตัวสำหรับ "สุนัข" และ "ลูกสุนัข" อธิบายเส้นทางในทิศทางที่เกือบจะเหมือนกัน ซึ่งค่อนข้างคล้ายคลึงกับทิศทางสำหรับ "แมว" อย่างไรก็ตามเวกเตอร์ที่ฝังไว้สำหรับ "สเก็ตบอร์ด" อธิบายการเดินทางในทิศทางที่แตกต่างกันมาก
หมายเหตุ
ตัวอย่างก่อนหน้านี้แสดงรูปแบบตัวอย่างง่ายๆ โดยที่การฝังแต่ละรายการมีเพียงสามมิติเท่านั้น โมเดลภาษาจริงยังมีมิติอื่นๆ อีกมากมาย
มีหลายวิธีที่คุณสามารถคํานวณการฝังที่เหมาะสมสําหรับชุดโทเค็นที่กําหนด รวมถึงอัลกอริทึมการสร้างโมเดลภาษา เช่น Word2Vec หรือ ตัวเข้ารหัส บล็อกในแบบจําลอง Transformer
ความสนใจ
ตัวเข้ารหัส และ ตัวถอดรหัส บล็อกในแบบจําลอง Transformer มีหลายเลเยอร์ที่สร้างเครือข่ายประสาทสําหรับแบบจําลอง เราไม่จําเป็นต้องลงในรายละเอียดของเลเยอร์เหล่านี้ทั้งหมด แต่มีประโยชน์ในการพิจารณาหนึ่งในเลเยอร์ประเภทที่ใช้ในทั้งสองบล็อก: เลเยอร์ ความสนใจ ความสนใจเป็นเทคนิคที่ใช้ในการตรวจสอบลำดับของโทเค็นข้อความและพยายามระบุปริมาณของความสัมพันธ์ระหว่างโทเค็นเหล่านั้น โดยเฉพาะอย่างยิ่ง การใส่ใจตนเอง เกี่ยวข้องกับการพิจารณาว่าโทเค็นอื่น ๆ รอบๆ โทเค็นเฉพาะหนึ่ง ๆ มีอิทธิพลต่อความหมายของโทเค็นนั้นอย่างไร
ในบล็อกตัวเข้ารหัส แต่ละโทเค็นจะถูกตรวจสอบอย่างรอบคอบในบริบท และการเข้ารหัสที่เหมาะสมจะถูกกําหนดสําหรับการฝังเวกเตอร์ ค่าเวกเตอร์จะขึ้นอยู่กับความสัมพันธ์ระหว่างโทเค็นกับโทเค็นอื่นๆ ที่มักปรากฏร่วมด้วย แนวทางเชิงบริบทนี้หมายความว่าคำเดียวกันอาจมีการฝังอยู่หลายรายการขึ้นอยู่กับบริบทที่ใช้ เช่น "เปลือกไม้" มีความหมายต่างจาก "ฉันได้ยินเสียงสุนัขเห่า"
ในบล็อกตัวถอดรหัส เลเยอร์ความสนใจจะถูกใช้เพื่อคาดการณ์โทเค็นถัดไปตามลําดับ สําหรับแต่ละโทเค็นที่สร้างขึ้น แบบจําลองมีเลเยอร์ความสนใจโดยคํานึงถึงลําดับโทเค็นจนถึงจุดนั้น แบบจําลองจะพิจารณาว่าโทเค็นใดมีอิทธิพลมากที่สุดเมื่อพิจารณาว่าโทเค็นถัดไปควรเป็นอย่างไร ตัวอย่างเช่น เมื่อกำหนดลำดับว่า "ฉันได้ยินเสียงสุนัข" เลเยอร์ความสนใจอาจกำหนดน้ำหนักให้กับโทเค็น "ได้ยิน" และ "สุนัข" มากขึ้นเมื่อพิจารณาคำถัดไปในลำดับ:
ฉัน ได้ยิน สุนัข [เห่า]
โปรดจําไว้ว่าเลเยอร์ความสนใจกําลังทํางานกับการแสดงเวกเตอร์ตัวเลขของโทเค็นไม่ใช่ข้อความจริง ในตัวถอดรหัส กระบวนการเริ่มต้นด้วยลําดับการฝังโทเค็นที่แสดงข้อความจะเสร็จสมบูรณ์ สิ่งแรกที่เกิดขึ้นคือเลเยอร์ การเข้ารหัสตามตำแหน่ง อีกเลเยอร์หนึ่งจะเพิ่มค่าลงในแต่ละการฝังเพื่อระบุตำแหน่งของเลเยอร์ดังกล่าวในลำดับ:
- [1,5,6,2] (I)
- [2,9,3,1] (ได้ยิน)
- [3,1,1,2] (a)
- [4,10,3,2] (สุนัข)
ในระหว่างการฝึกเป้าหมายคือการทํานายเวกเตอร์สําหรับโทเค็นสุดท้ายในลําดับที่ยึดตามโทเค็นก่อนหน้า เลเยอร์ความสนใจจะกำหนด น้ำหนัก เชิงตัวเลขให้กับแต่ละโทเค็นในลำดับที่ผ่านมา จะใช้ค่าดังกล่าวในการคำนวณเวกเตอร์ที่มีน้ำหนักซึ่งจะสร้าง คะแนนความสนใจ ที่สามารถนำไปใช้คำนวณเวกเตอร์ที่เป็นไปได้สำหรับโทเค็นถัดไปได้ ในทางปฏิบัติ เทคนิคที่เรียกว่า Multi-Head Attention ใช้องค์ประกอบที่แตกต่างกันของการฝังเพื่อคํานวณคะแนนความสนใจหลายคะแนน จากนั้นจะใช้เครือข่ายประสาทเพื่อประเมินโทเค็นที่เป็นไปได้ทั้งหมดเพื่อกําหนดโทเค็นที่น่าจะเป็นไปได้มากที่สุดที่จะดําเนินการตามลําดับต่อไป กระบวนการดำเนินต่อไปแบบวนซ้ำสำหรับแต่ละโทเค็นในลำดับ โดยที่ลำดับเอาท์พุทจนถึงขณะนี้ถูกใช้แบบถดถอยเป็นอินพุตสำหรับการวนซ้ำครั้งถัดไป ซึ่งก็คือการสร้างเอาท์พุทครั้งละหนึ่งโทเค็น
ภาพเคลื่อนไหวต่อไปนี้แสดงการแทนแบบง่ายของวิธีการทํางาน ในความเป็นจริง การคํานวณที่ดําเนินการโดยเลเยอร์ความสนใจมีความซับซ้อนมากขึ้น แต่สามารถทําให้หลักการง่ายขึ้นตามที่แสดง:

- ลําดับของการฝังโทเค็นถูกป้อนลงในเลเยอร์ความสนใจ โทเค็นแต่ละรายการจะแสดงเป็นเวกเตอร์ของค่าตัวเลข
- เป้าหมายของตัวถอดรหัสคือการทํานายโทเค็นถัดไปในลําดับ ซึ่งจะเป็นเวกเตอร์ที่สอดคล้องกับการฝังในคําศัพท์ของแบบจําลอง’
- เลเยอร์ความสนใจจะประเมินลําดับจนถึงตอนนี้และกําหนดน้ำหนักให้กับแต่ละโทเค็นเพื่อแสดงอิทธิพลสัมพัทธ์ของพวกเขาในโทเค็นถัดไป
- น้ำหนักสามารถใช้ในการคํานวณเวกเตอร์ใหม่สําหรับโทเค็นถัดไปด้วยคะแนนความสนใจ Multi-Head Attention ใช้องค์ประกอบที่แตกต่างกันในการฝังเพื่อคํานวณโทเค็นทางเลือกหลายรายการ
- เครือข่ายประสาทที่เชื่อมต่ออย่างสมบูรณ์ใช้คะแนนในเวกเตอร์จากการคํานวณเพื่อคาดการณ์โทเค็นที่น่าจะเป็นไปได้มากที่สุดจากคําศัพท์ทั้งหมด
- เอาท์พุทที่ทํานายจะถูกผนวกเข้ากับลําดับจนถึงปัจจุบันซึ่งใช้เป็นข้อมูลป้อนเข้าสําหรับการทําซ้ําครั้งต่อไป
ในระหว่างการฝึกลําดับโทเค็นที่แท้จริงเป็นที่รู้จักกัน เราเพียงปกปิดโทเค็นที่มาภายหลังในลําดับกว่าตําแหน่งโทเค็นที่กําลังพิจารณา เช่นเดียวกับในเครือข่ายประสาทใด ๆ ค่าที่ทํานายสําหรับเวกเตอร์โทเค็นจะถูกเปรียบเทียบกับค่าจริงของเวกเตอร์ถัดไปในลำดับ และการสูญเสียจะถูกคำนวณ น้ำหนักจะถูกปรับทีละน้อยเพื่อลดการสูญเสียและปรับปรุงแบบจําลอง เมื่อใช้สำหรับการอนุมาน (คาดการณ์ลำดับโทเค็นใหม่) เลเยอร์ความสนใจที่ได้รับการฝึกจะใช้การถ่วงน้ำหนักเพื่อคาดการณ์โทเค็นที่น่าจะเป็นไปได้มากที่สุดในคำศัพท์ของแบบจำลองที่สอดคล้องทางความหมายกับลำดับจนถึงขณะนี้
ทั้งหมดนี้หมายความว่าแบบจําลอง Transformer เช่น GPT-4 (แบบจําลองที่อยู่เบื้องหลัง ChatGPT และ Bing) ถูกออกแบบมาเพื่อป้อนข้อความ (เรียกว่าพร้อมท์) และสร้างผลลัพธ์ที่ถูกต้องทางไวยากรณ์ (เรียกว่า เสร็จสมบูรณ์) โดยความเป็นจริงแล้ว “ความมหัศจรรย์” ของแบบจําลองนี้อยู่ที่ความสามารถในการร้อยเรียงประโยคที่มีความสอดคล้องกันเข้าด้วยกัน ความสามารถนี้ไม่ได้บ่งบอกถึง "ความรู้" หรือ "สติปัญญา" ของแบบจำลอง เพียงแค่มีคำศัพท์จำนวนมากและความสามารถในการสร้างลำดับคำที่มีความหมายเท่านั้น อย่างไรก็ตาม สิ่งที่ทําให้โมเดลภาษาขนาดใหญ่อย่าง GPT-4 มีประสิทธิภาพมากคือปริมาณข้อมูลที่แท้จริงที่ได้รับการฝึก (ข้อมูลสาธารณะและข้อมูลที่ได้รับอนุญาตจากอินเทอร์เน็ต) และความซับซ้อนของเครือข่าย การดําเนินการนี้จะเปิดใช้งานแบบจําลองเพื่อสร้างความสมบูรณ์ที่ยึดตามความสัมพันธ์ระหว่างคําในคําศัพท์ที่ได้รับการฝึกแบบจําลอง มักจะสร้างเอาต์พุตที่แยกไม่ออกจากการตอบสนองของมนุษย์ต่อพร้อมท์เดียวกัน